Bayesian Inference:
What is the posterior and why should I care?
Data Philly, Feb. 2024
Dante Gates
Premise
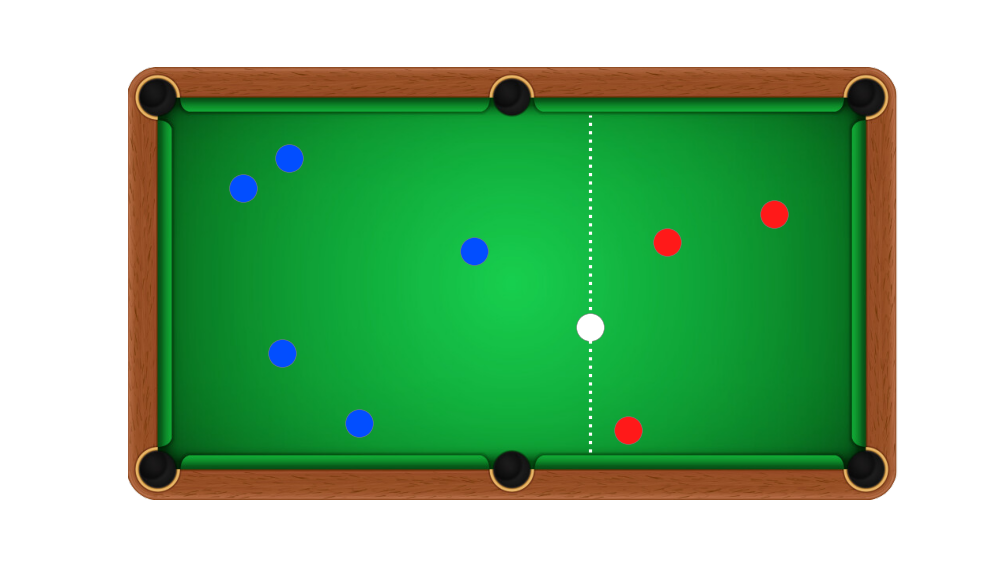
- An initial ball is rolled (colored white)
- Subsequent rolls that fall to the left, score for Alice (colored blue)
- Rolls that fall to the right score for Bob (colored red)
- First player to reach 6 points wins
The problem

Alice has scored 5 times, Bob has scored 3, what was the position of the first roll?
Model likelihood: P(y\vert D)

Model priors and likelihood
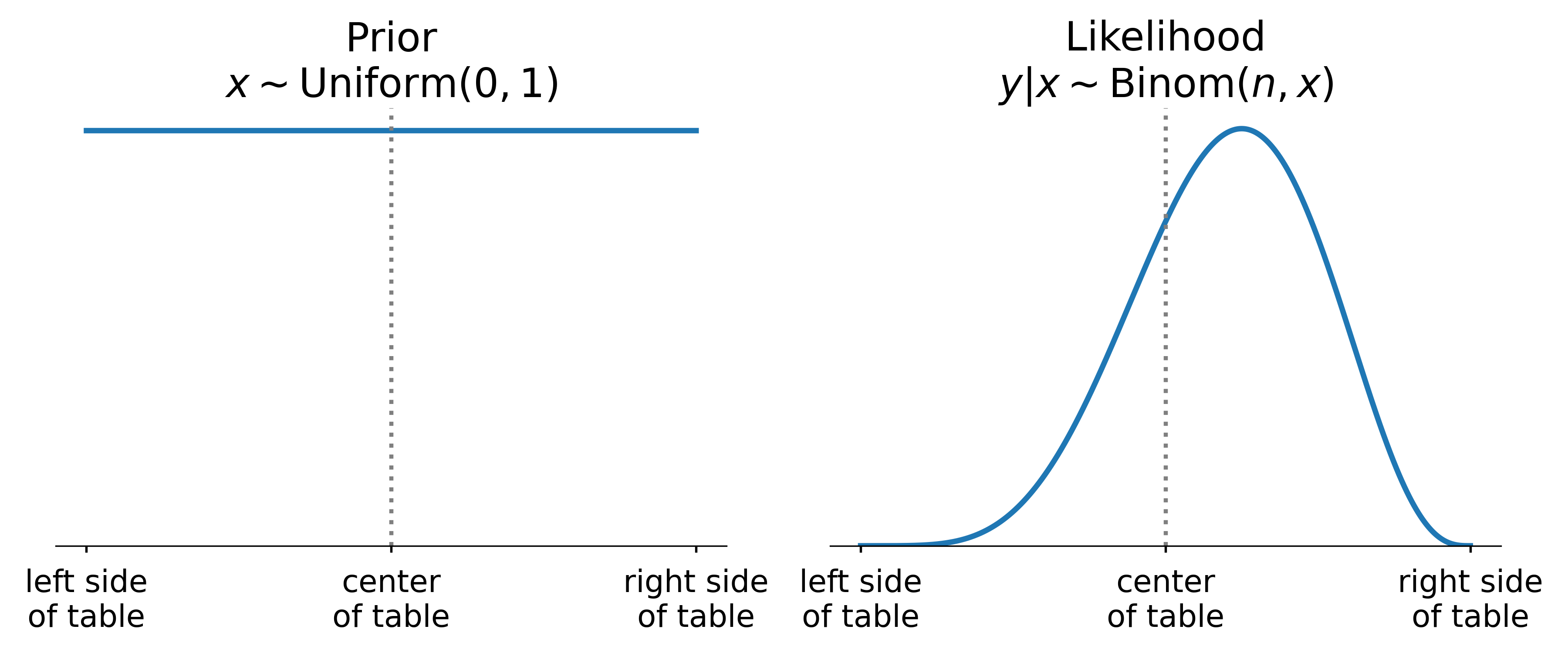
Where was the first roll?
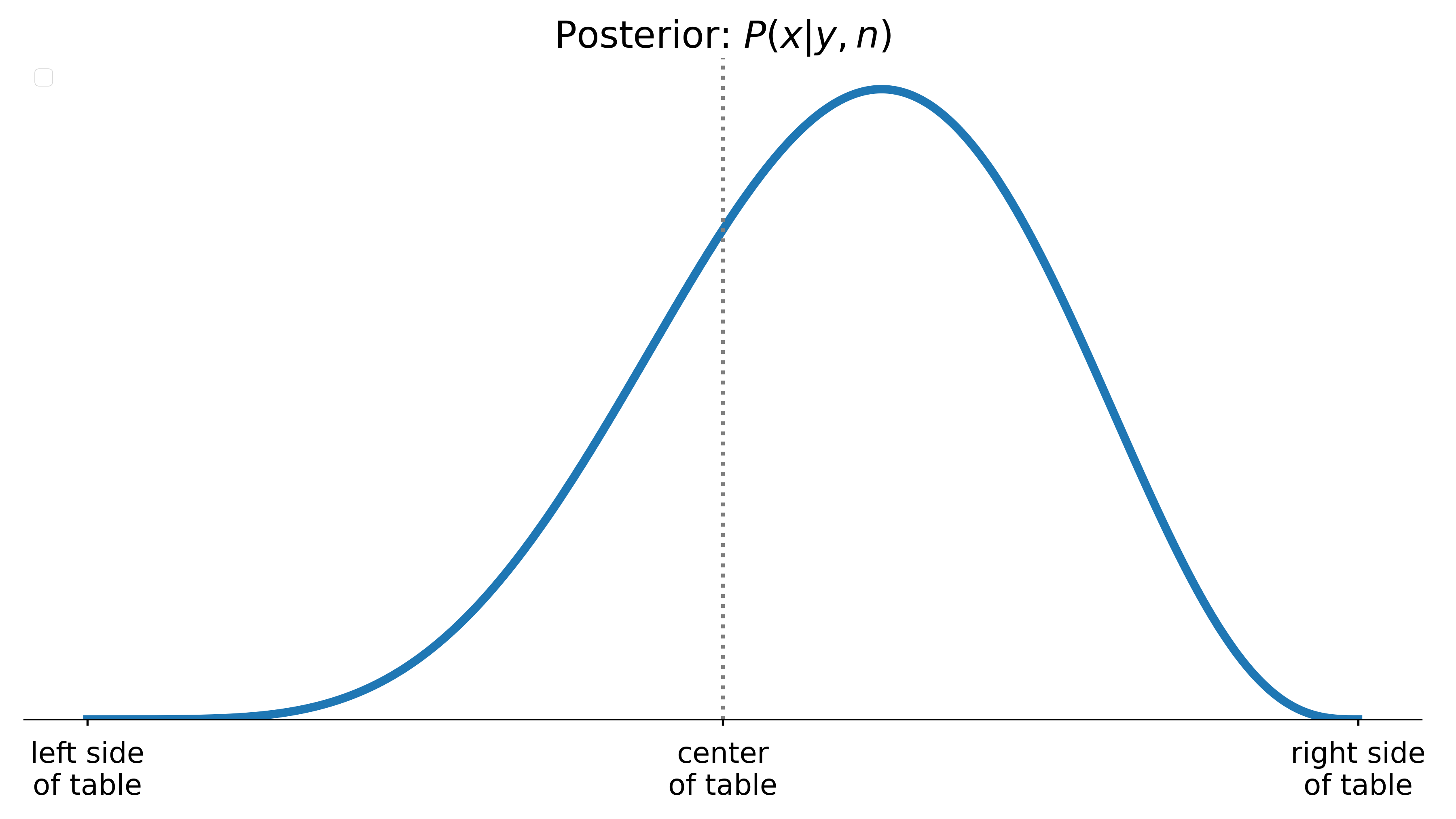
Posterior means
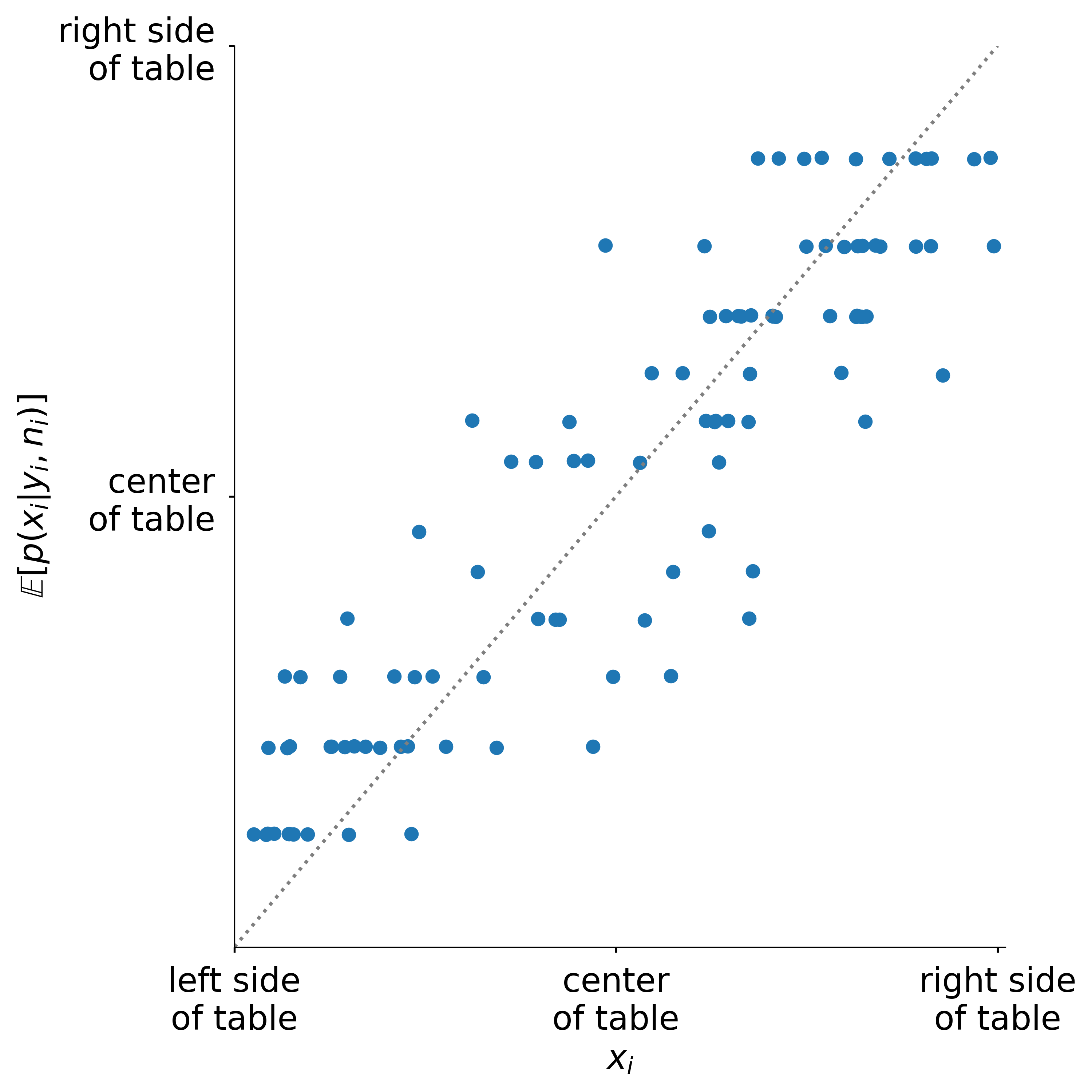
If we play this game many times the posterior mean produces reliable estimates of the position of the first roll
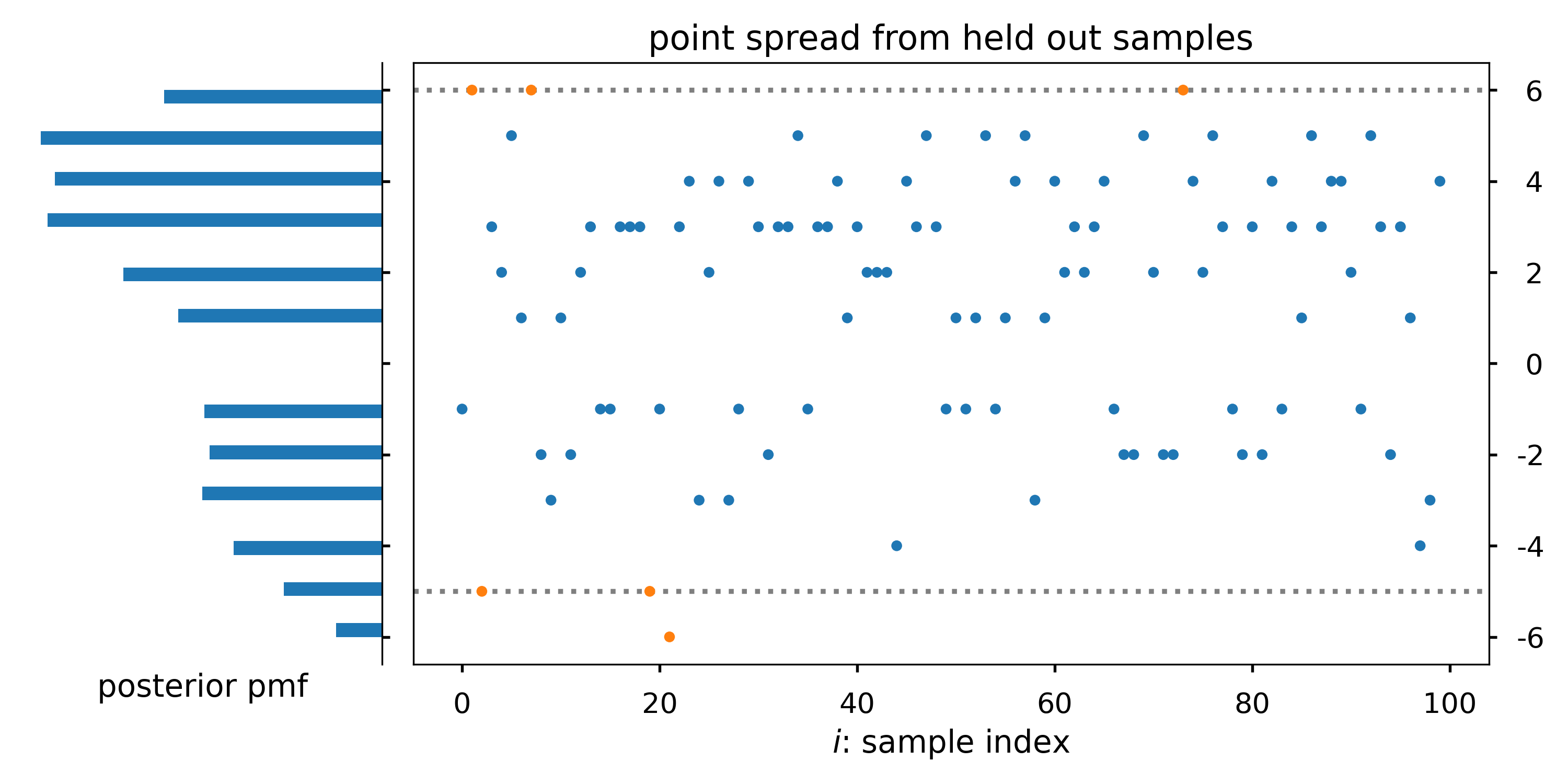
Posterior intervals
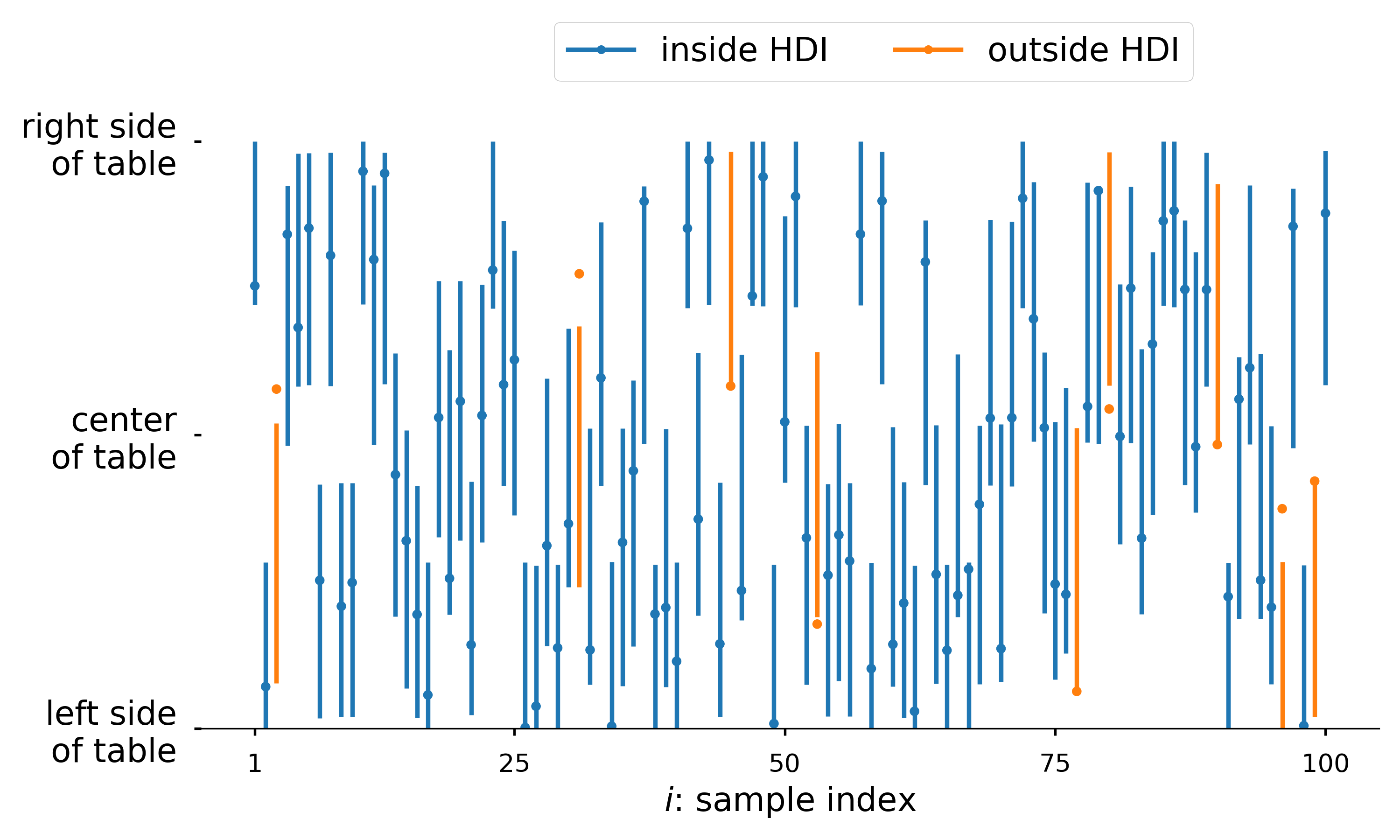
The 90% HDI of our posterior contains x_{i} ~90% of the time as expected
Enter HMC
import pymc as pm
alice, bob = 5, 3
with pm.Model() as model:
x = pm.Uniform('x', 0, 1)
likelihood = pm.Binomial('likelihood',
p=x,
n=alice+bob,
observed=alice)
idata = pm.sample()
plt.hist(idata.posterior.x)Enter HMC
import pymc as pm
alice, bob = 5, 3
with pm.Model() as model:
x = pm.Uniform('x', 0, 1)
likelihood = pm.Binomial('likelihood',
p=x,
n=alice+bob,
observed=alice)
idata = pm.sample()
# ↓↓↓ approximate the integration ↓↓↓
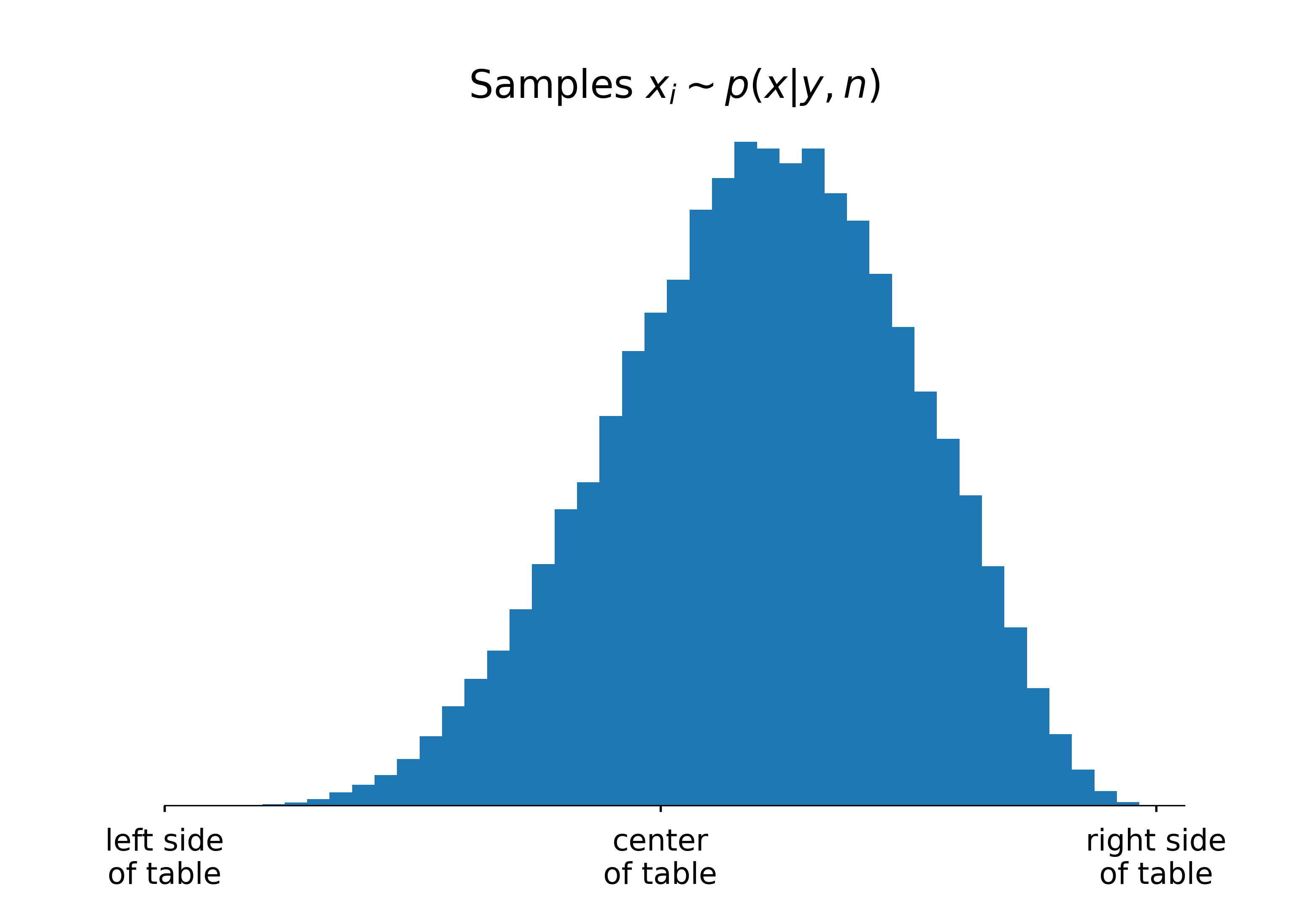
np.power(1-idata.posterior.x, 3).mean()Random variables in, random variables out
We also expect reliable long term behavior from the posterior predictive distributions. Thus, simulations of, e.g., point spread should exhibit these properties
Properties of the Kelly Criterion
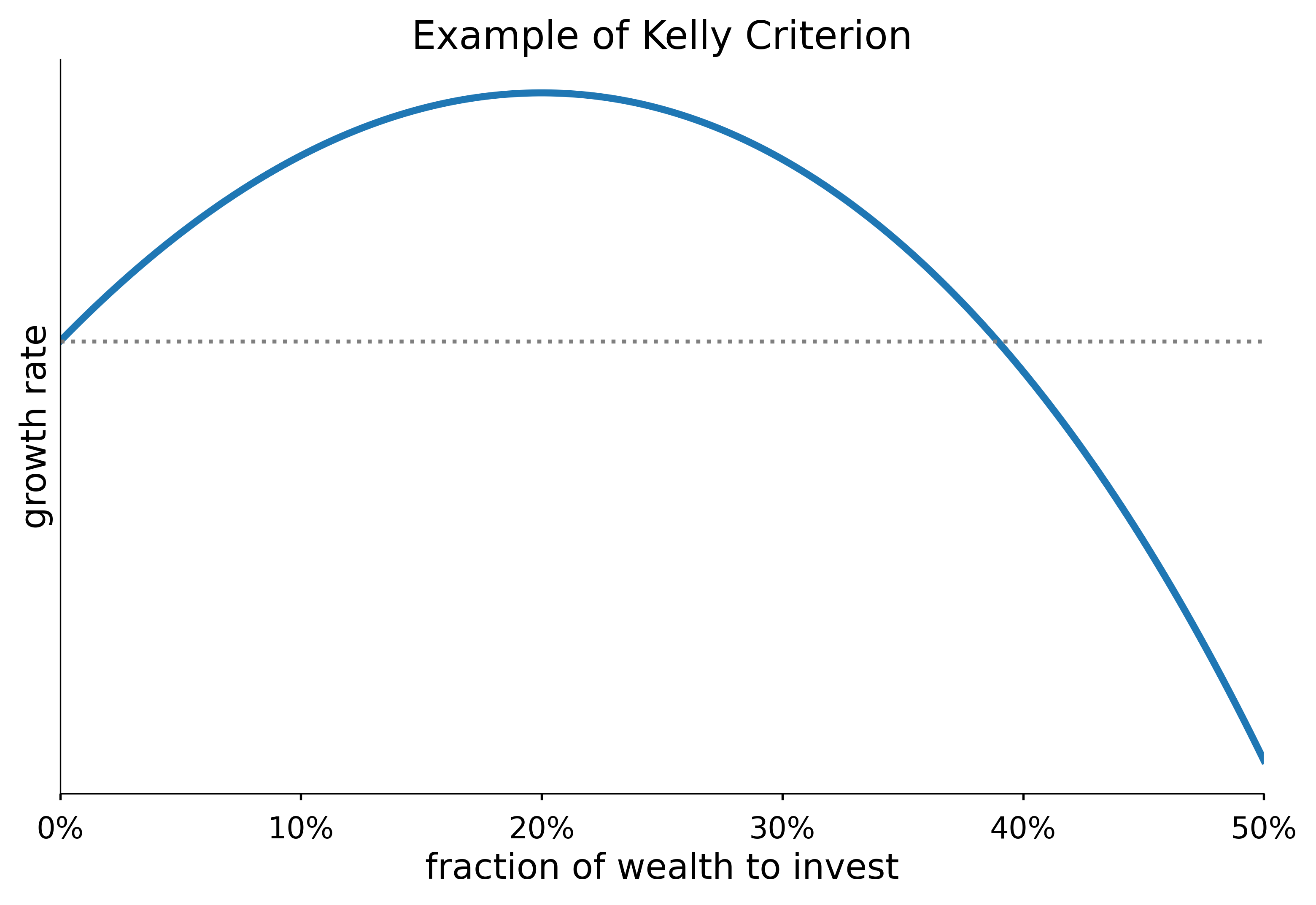
Properties of the Kelly Criterion include: a global maximum, a point of diminishing returns and “greed” that produces inevitable ruin.
Ed Thorp and the Kelly criterion
What if we want to apply the Kelly criterion to a “continuous gambling game”, such as the stock market?
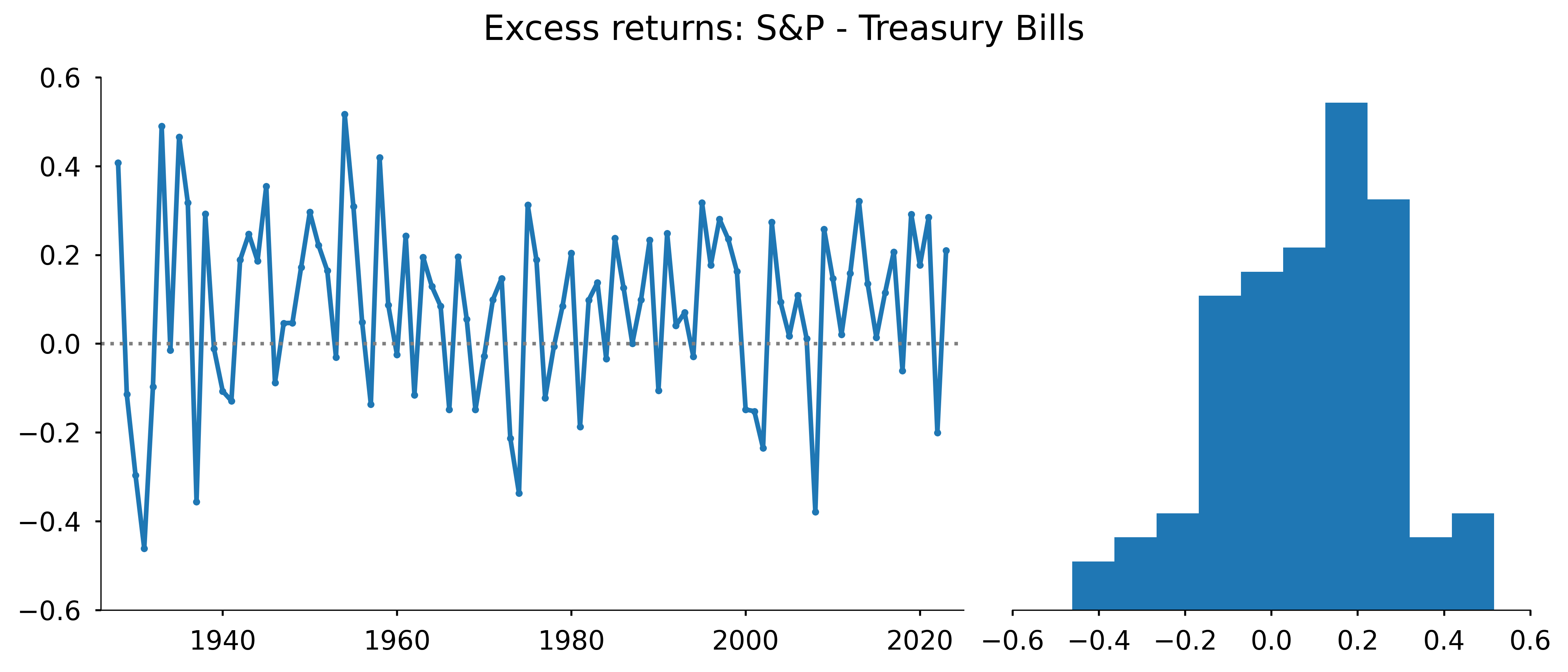
Thorp’s conclusion: invest heavily
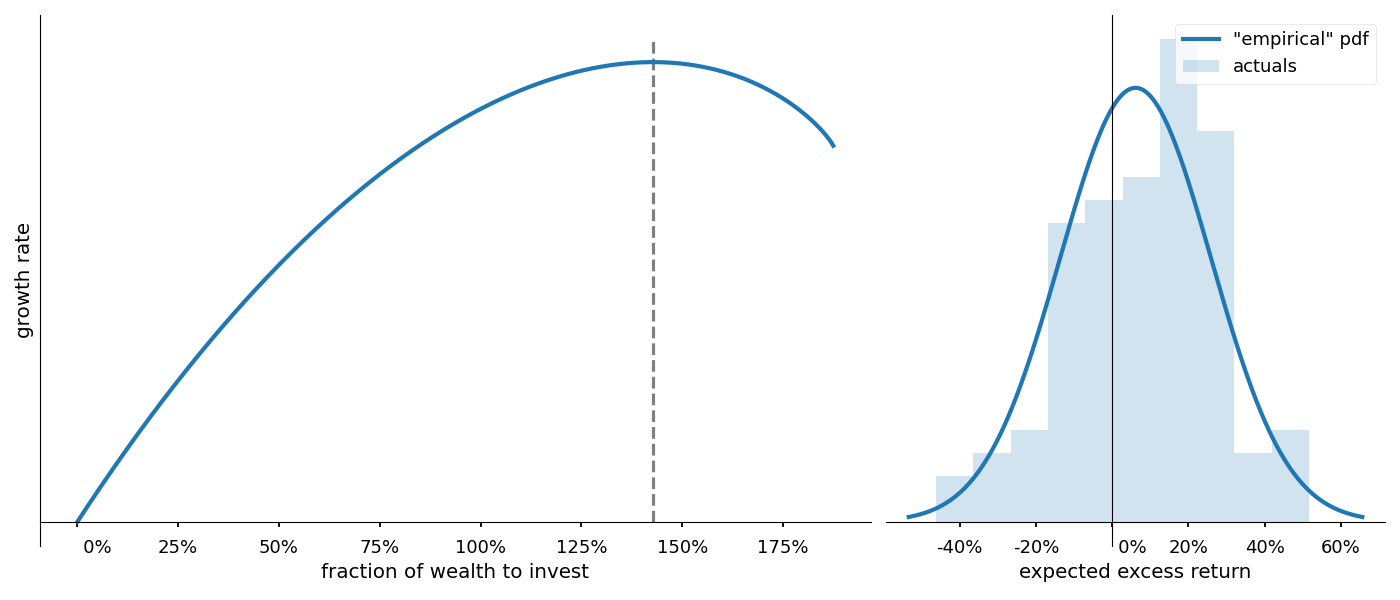
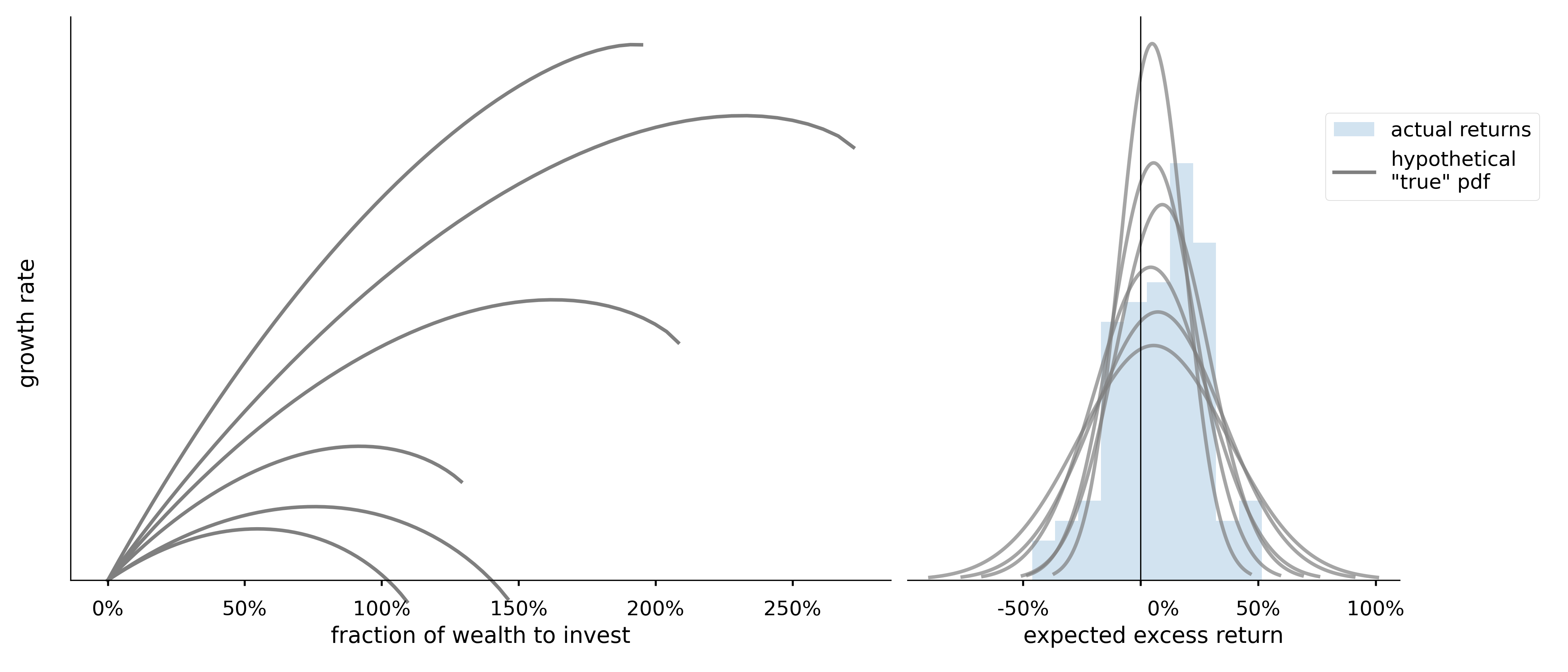
What is the true data generating distribution?
Code
import pymc as pm
with pm.Model() as model:
μ = pm.Gamma('μ', mu=.04, sigma=.005)
σ = pm.Gamma('σ', mu=.2, sigma=.05)
likelihood = pm.Normal('likelihood', mu=μ, sigma=σ, observed=r)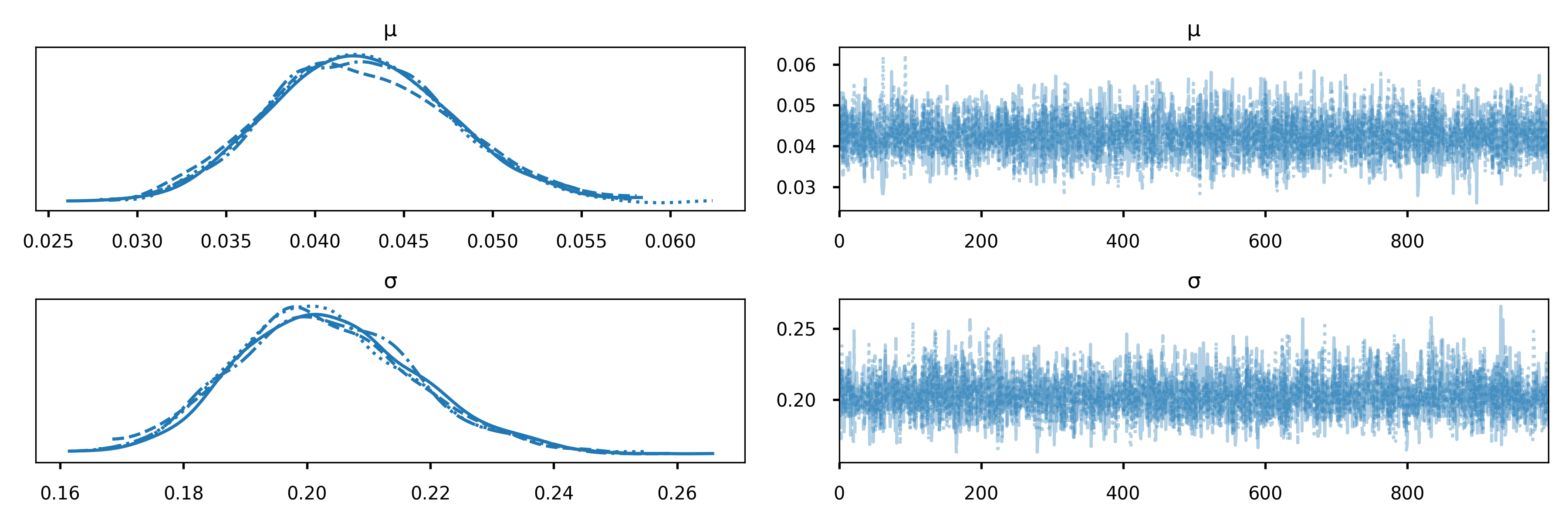
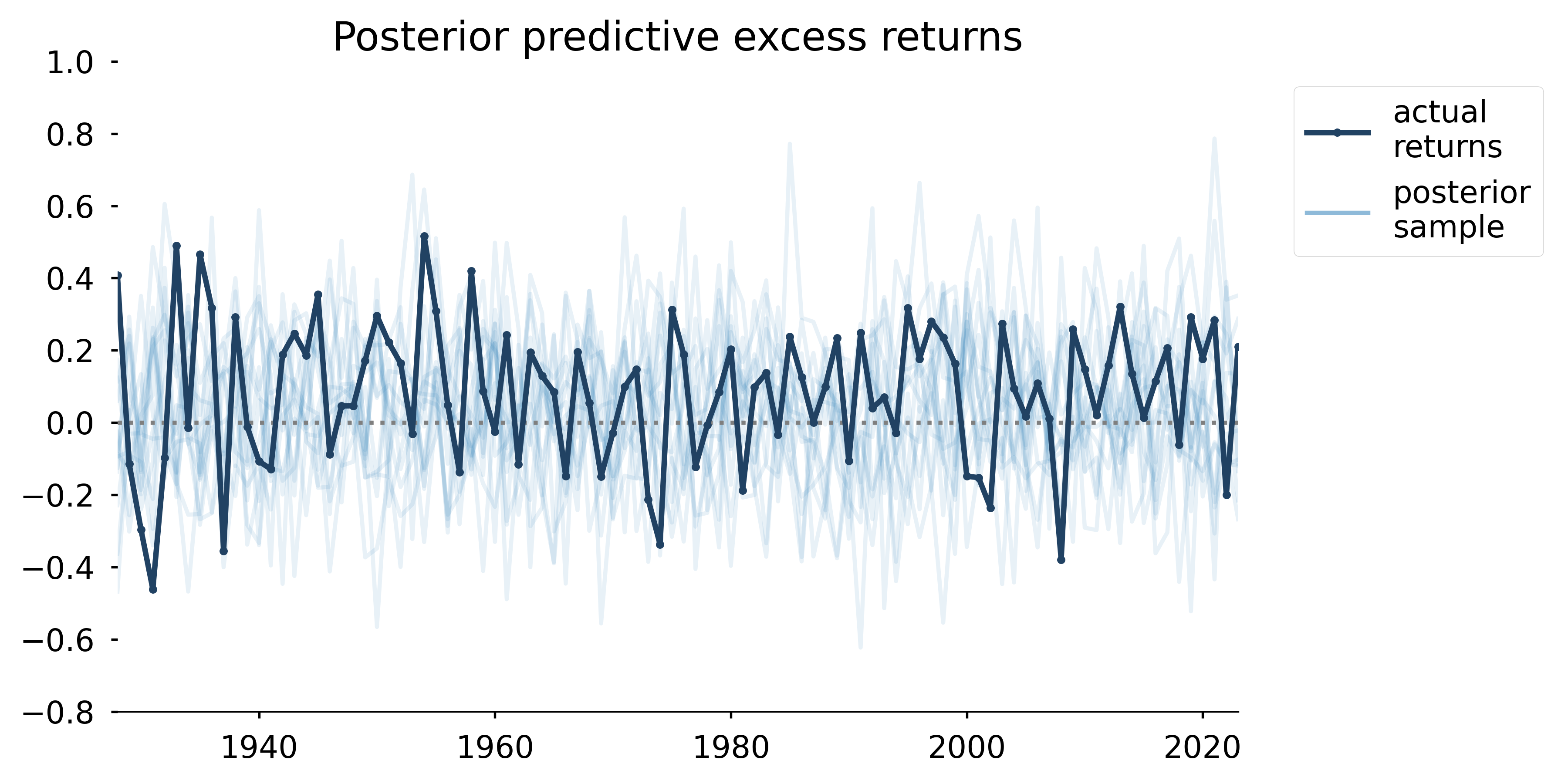
Posterior predictive samples
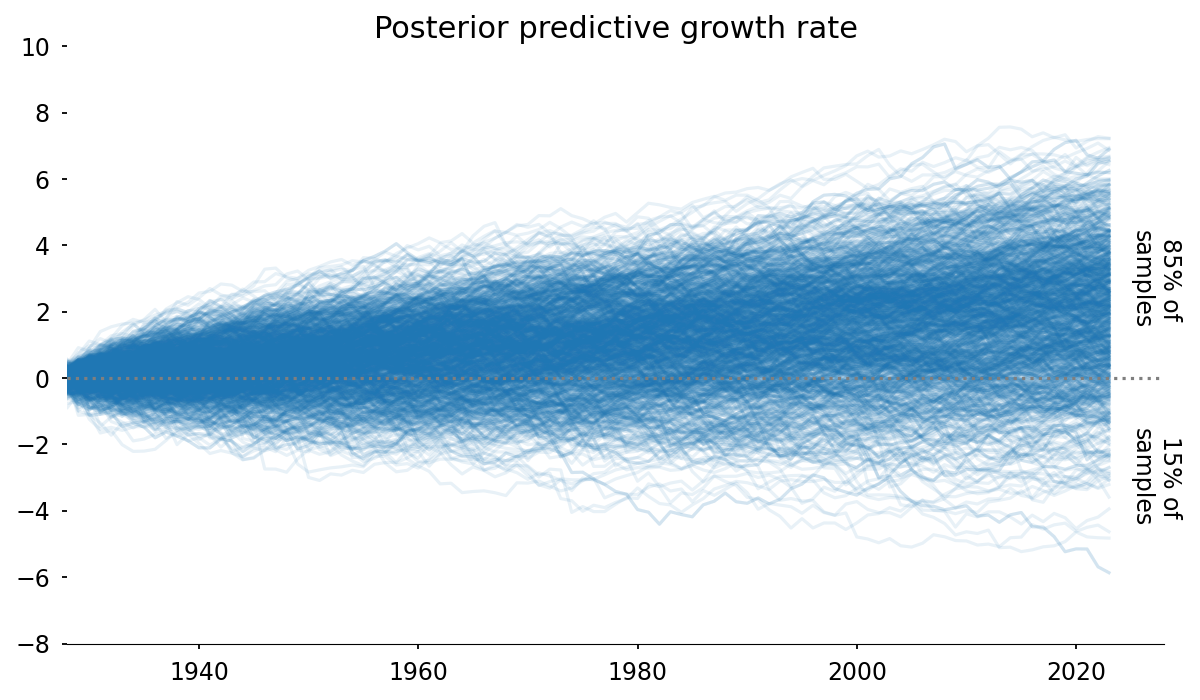
Posterior predictive growth rate
Not only can we extract the usual summary statistics from the posterior predictive, but we can ask questions like, “how often do we expect this strategy to produce a loss after a 100 year investment period?”
Imagine: these were conversion rates
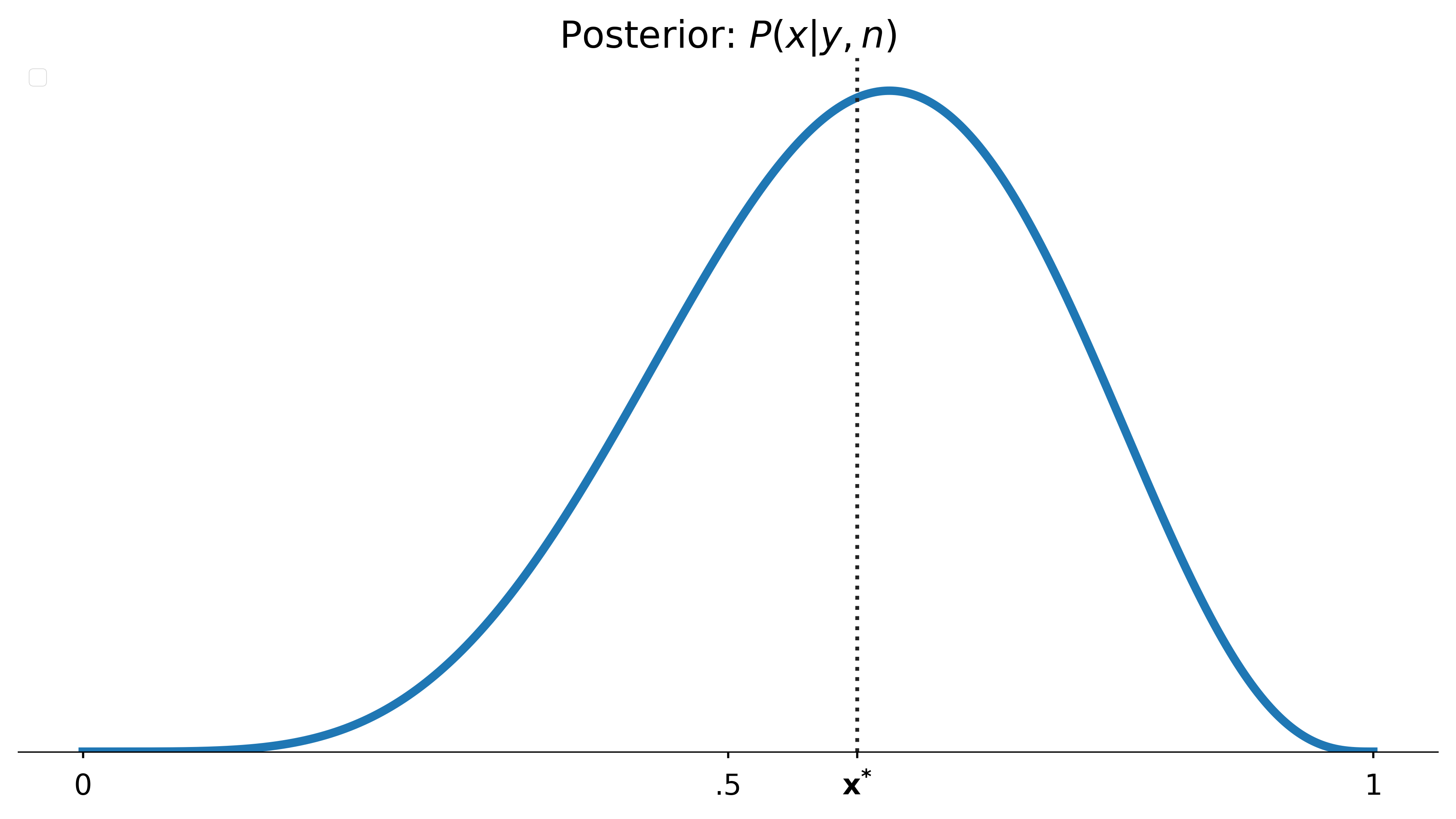

Imagine: these were conversion rates
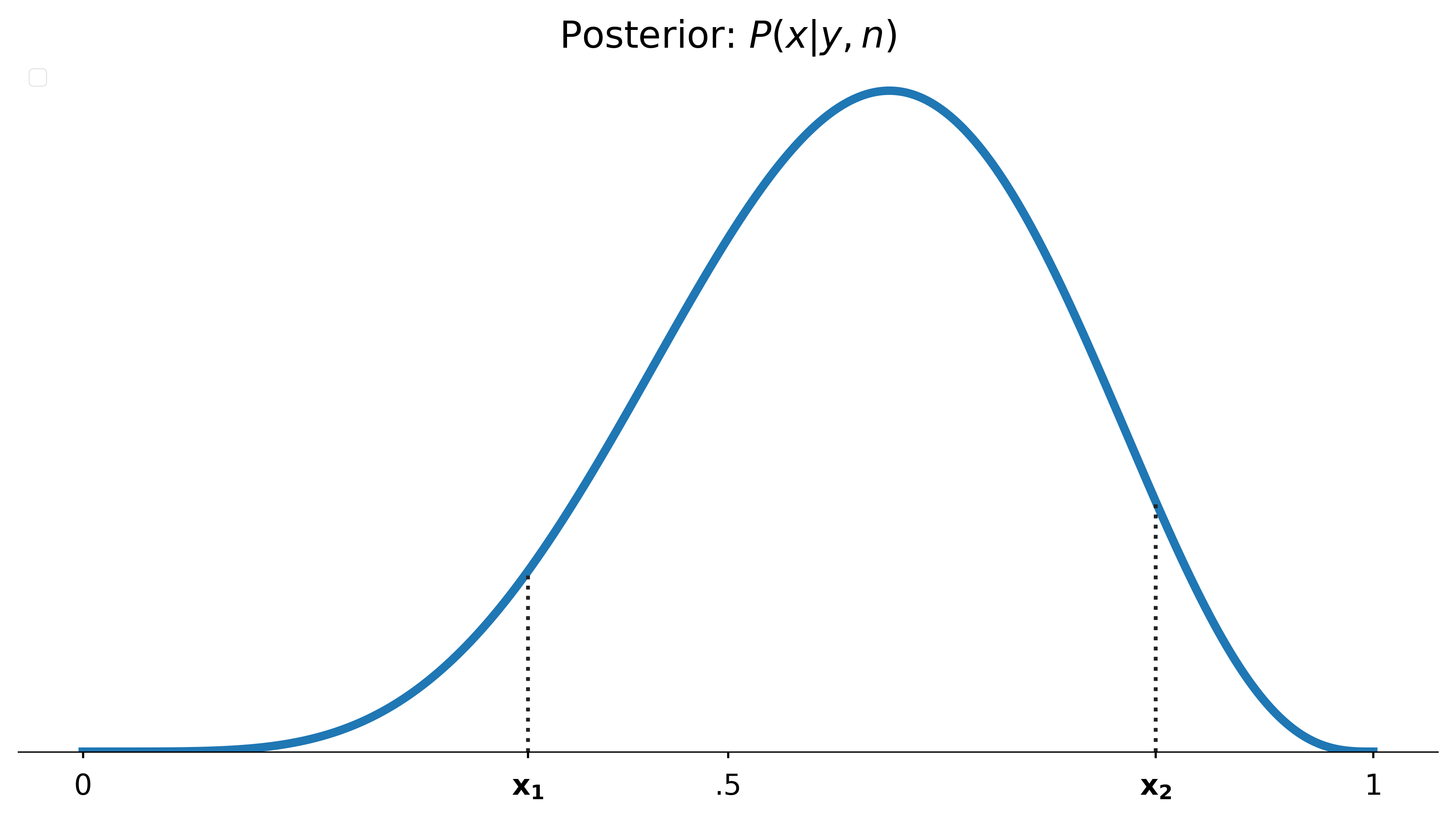

Resist the temptation

Similar to point-spread
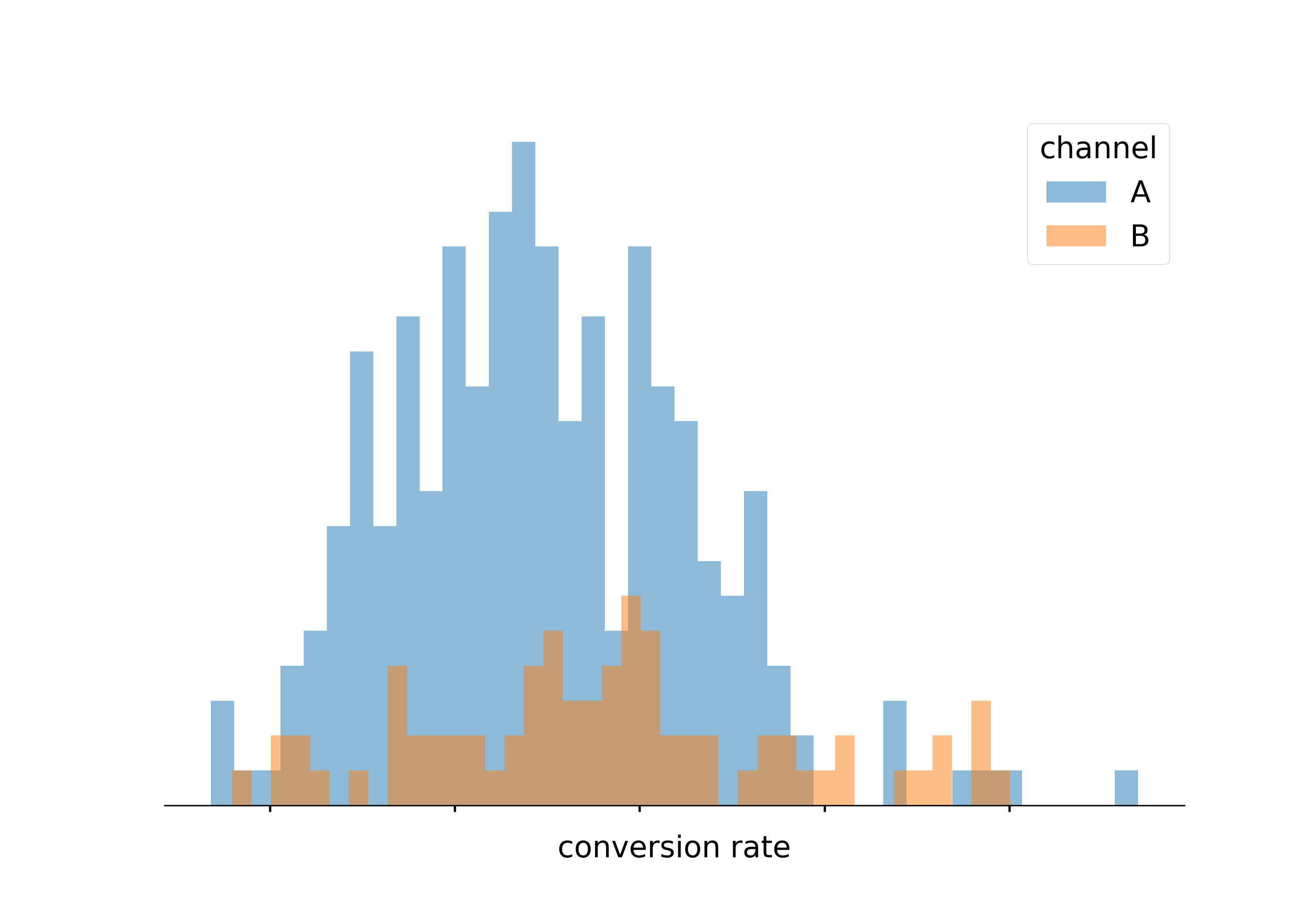
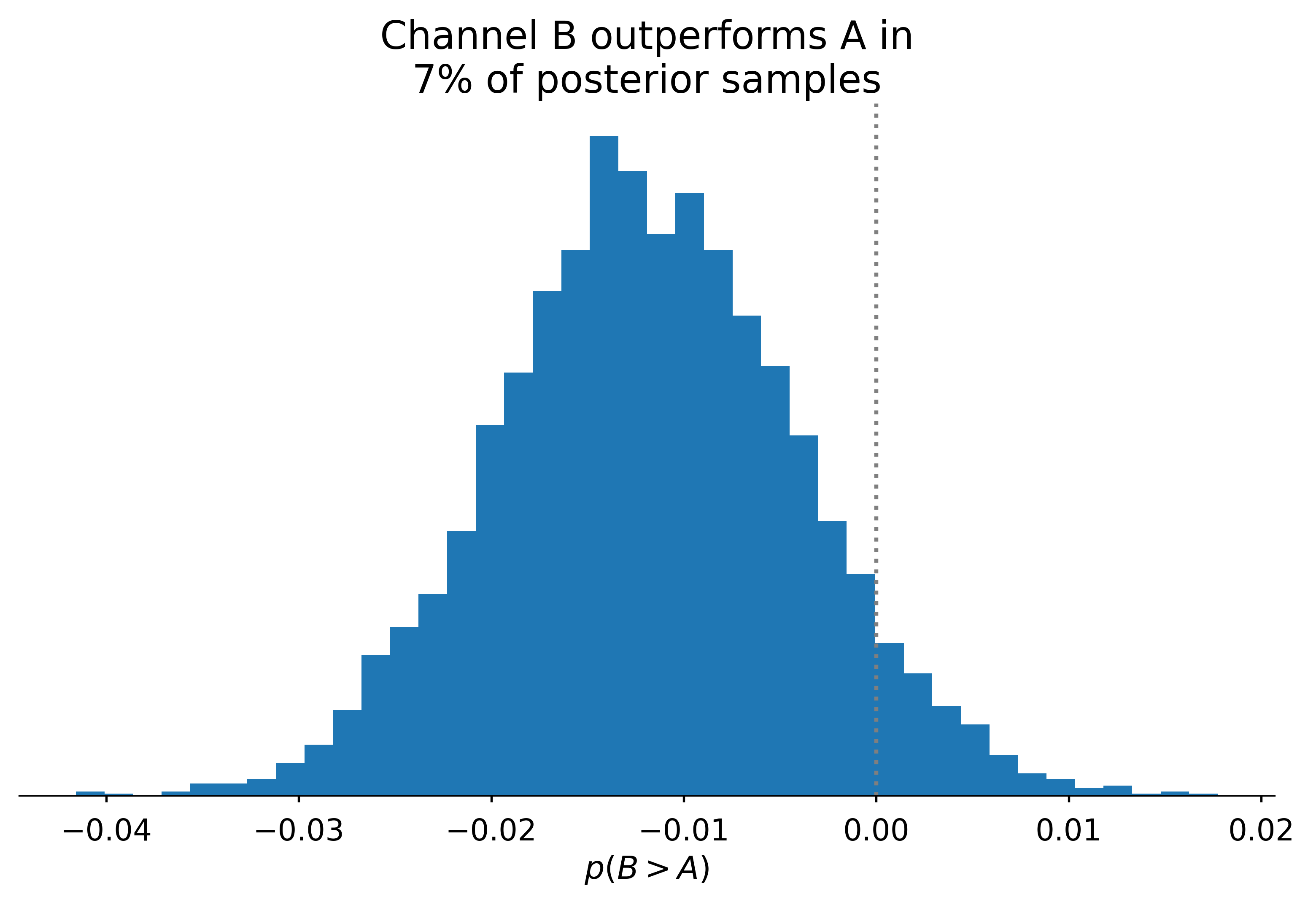
We could consider the probability that one “channel” will outperform another: i.e. p(c_{1} < c_{2})
Comparison
with pm.Model() as model:
θ = pm.Beta('θ', 1, 1, size=2)
pm.Binomial(
'y1', p=θ[0], n=n1, observed=y1
)
pm.Binomial(
'y2', p=θ[1], n=n2, observed=y2
)
idata = pm.sample()
θ_post = idata.posterior.θ
(θ_post[..., 1] > θ_post[..., 0]).mean()Thompson sampling
Thompson sampling allows for “live” A/B testing, where action A is taken according to the probability that A > B.
Anomaly detection
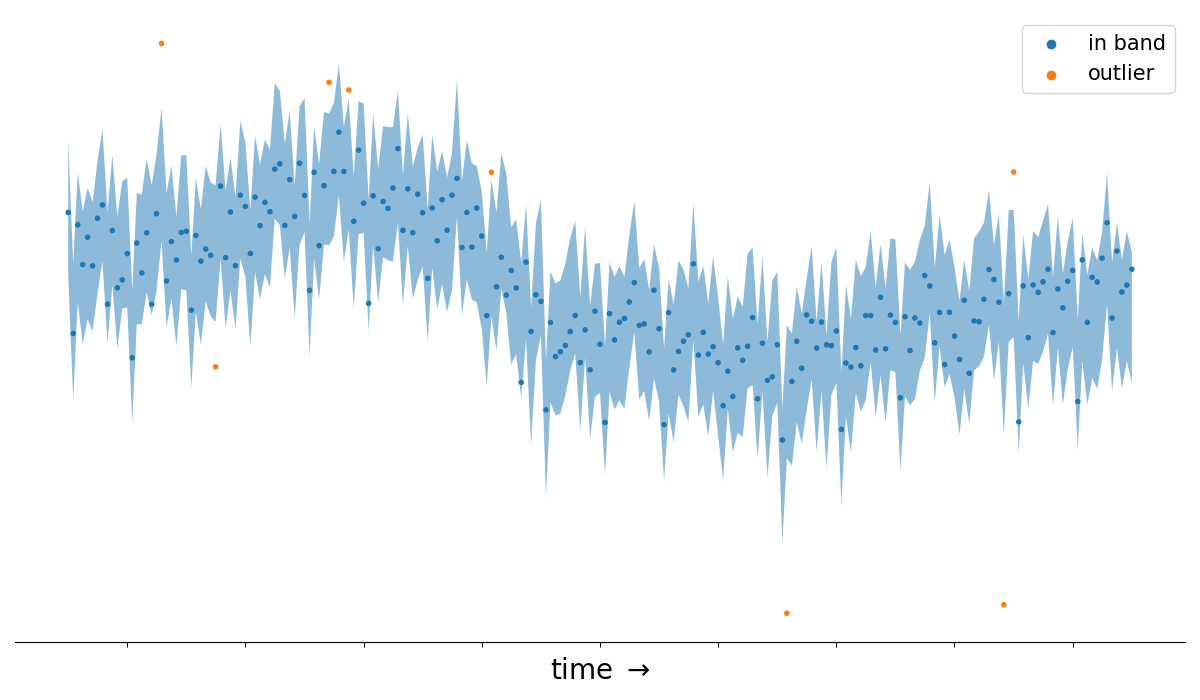
These properties also hold for more complex generative models such time series forecasts with trend and seasonal components.
Husband and Father
Philly data scientist
wrote a haiku once