
Keras Feature Columns
tensorflow's feature columns are a great idea. However the implementation leaves much to be desired.
In this post we’ll discuss what makes feature columns a great idea and suggest using an alternative keras implementation that exposes a much more user-friendly interface. We’ll also show how examples of how to use the keras implementation.
Why feature columns?
What makes feature columns a great idea?
One of the great ideas behind feature columns is the ability to Specify how to preprocess individual features (with support for normalization, one hot encoding, feature hashing, etc.). The main advantage this gives us is we can build a dataset where different columns will be processed differently.
The second great idea behind feature columns is it allows you to tie features into your model. For example, you can specify that the model should learn an embedding for a given feature.
Update: For a walk through of using native tensorflow 2.0 feature columns with keras see my newer post.
keras feature columns
The keras implementation itself can be found here.
First we’ll consider a trivial example of building a simple feed forward network.
import numpy as np
import pandas as pd
import keras
import feature_columns
X = pd.DataFrame({
'feature1': np.random.randint(10, size=100),
'feature2': np.random.randint(100, size=100),
'feature3': np.random.rand(100)
})
y = np.random.rand(100)
features = feature_columns.FeatureSet(
# Categorical features can be instantiated with the actual training data.
# This frees the user from having to determine the vocabulary, input
# dimmension, etc.
feature_columns.EmbeddedFeature('feature1', X=['feature1'], embedding_dim=10),
feature_columns.OneHotFeature('feature2', X=X['feature2']),
feature_columns.NumericFeature('feature3', normalizer=np.log10)
)
x = keras.layers.Dense(50, activation='relu')(features.output)
x = keras.layers.Dense(50, activation='relu')(x)
x = keras.layers.Dense(1, activation='sigmoid')(x)
model = keras.models.Model(inputs=features.inputs, outputs=x)
model.summary()
model.compile(loss='mse', optimizer='adam')
_ = model.fit(features.fit_transform(X), y)
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
feature1_3 (InputLayer) (None, 1) 0
__________________________________________________________________________________________________
embedding_3 (Embedding) (None, 1, 10) 20 feature1_3[0][0]
__________________________________________________________________________________________________
flatten_2 (Flatten) (None, 10) 0 embedding_3[0][0]
__________________________________________________________________________________________________
feature2_3 (InputLayer) (None, 67) 0
__________________________________________________________________________________________________
feature3_3 (InputLayer) (None, 1) 0
__________________________________________________________________________________________________
concatenate_2 (Concatenate) (None, 78) 0 flatten_2[0][0]
feature2_3[0][0]
feature3_3[0][0]
__________________________________________________________________________________________________
dense_4 (Dense) (None, 50) 3950 concatenate_2[0][0]
__________________________________________________________________________________________________
dense_5 (Dense) (None, 50) 2550 dense_4[0][0]
__________________________________________________________________________________________________
dense_6 (Dense) (None, 1) 51 dense_5[0][0]
==================================================================================================
Total params: 6,571
Trainable params: 6,571
Non-trainable params: 0
__________________________________________________________________________________________________
Epoch 1/1
100/100 [==============================] - 0s 3ms/step - loss: 0.0873
Predicting web traffic
Now let’s take a look at a non-trivial example. We’ll use the keras feature columns to create the input for an LSTM that predicts web traffic using data from this kaggle competition.
Note for brevity of this post, I’ve cut out some of the data processing steps. If you want to see the example end to end check out this notebook.
import feature_columns
import keras
import numpy as np
static_feature_set = feature_columns.FeatureSet(
feature_columns.OneHotFeature('agent', X=page_features.agent),
feature_columns.OneHotFeature('access', X=page_features.access),
feature_columns.EmbeddedFeature('project', X=page_features.project, embedding_dim=3)
)
def normalizer(x):
return np.log10(x+1e-1)
pageviews_feature_set = feature_columns.FeatureSet(*[
feature_columns.NumericFeature(f'pageviews_{i}', normalizer=normalizer) for i in range(30)
])
sequences = [keras.layers.Concatenate()([static_feature_set.output, f.output])
for f in pageviews_feature_set.features]
all_feature_set = feature_columns.FeatureSet.combine(static_feature_set, pageviews_feature_set)
Using TensorFlow backend.
concat = keras.layers.Concatenate()
reshape = keras.layers.Reshape((30, -1))
lstm_input = reshape(concat(sequences))
lstm = keras.layers.LSTM(512)(lstm_input)
output = keras.layers.Dense(1)(lstm)
model = keras.models.Model(inputs=all_feature_set.inputs, outputs=output)
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
SVG(model_to_dot(model).create(prog='dot', format='svg'))

model.fit(
X_train, np.log10(y_train+1),
epochs=3,
validation_data=(X_test, np.log10(y_test+1)))
Train on 69381 samples, validate on 22838 samples
Epoch 1/10
69381/69381 [==============================] - 343s 5ms/step - loss: 0.0277 - val_loss: 0.0228
Epoch 2/10
69381/69381 [==============================] - 336s 5ms/step - loss: 0.0203 - val_loss: 0.0194
Epoch 3/10
69381/69381 [==============================] - 333s 5ms/step - loss: 0.0195 - val_loss: 0.0197 ```
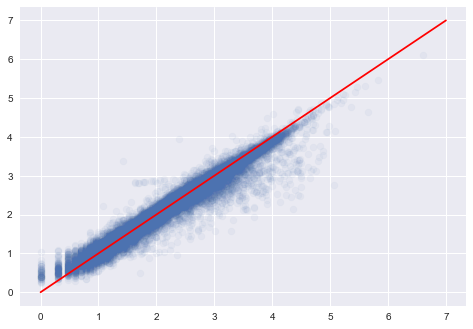
import matplotlib.pyplot as plt
plt.style.use('seaborn')
p = model.predict(X_test)[:, 0]
plt.scatter(np.log10(y_test+1), p, alpha=0.05)
plt.plot([0, 7], [0, 7], color='r')
[<matplotlib.lines.Line2D at 0x117b77320>]
Why reinvent the wheel?
Why not use tensorflow's feature columns?
While tensorflow's feature columns are a great idea that support both a preprocessing pipeline and a set of basic transformations easily applied to a variety of industry problems, I found that, unfortunately, working with feature columns is awkward if you want to do anything slightly outside the box. In my experience this is mainly due to the fact that feature columns only work with tensorflow estimators.
My first attempt at working with feature columns was to try and connect feature columns to keras models. Why? Because for time series applications at work I would like to have a convenient way to feed a mixture of numeric and categorical values to an LSTM. Feature columns sound like they should make the first part easy and keras makes training an LSTM easy. Since tensorflow now houses a keras API I thought this would be straightforward. I was wrong. The key to getting this to work is to convert your keras model to a tensorflow estimator with tf.keras.estimator.model_to_estimator. However, actually connecting your feature columns to your keras model is far from trivial requiring more code than seems worth the trouble.
Taking the hint from my first stab at using feature columns, my second attempt was to stick with tensorflow estimators and avoid keras altogether. In this case I simply tried to re-implement a simple linear model I implemented for a project at work some time ago using feature columns and tensorflow's linear regression estimator. In a short period of time I was able to get the model training. However, there was some outliers that the model predicted poorly on. No problem - I already faced this in my initial implementation and knew that using huber loss would likely remedy the issue. However, after spending more time researching how to switch from the default loss function (MSE) to huber loss than I wish I had I concluded that it isn’t possible to do so without writing your own custom estimator. But writing your own estimator was a deal breaker for me - for me, the whole appeal of feature columns was having something that worked out of the box.
My last comment is that it’s worth noting that the web is pretty silent on how to do anything with tensorflow estimators outside of what you can find in the docs. This stackoverlfow post (accessed 7/17/18) is pretty indicative of the kind of help you’ll find on the subject… nothing.